Now I know this may be sacrilege, but I have and use a JD system I love very much.
I find that the main advantages of a JD system is absolutely knowing where something might be, having a clear bird’s eye view of my entire system’s scope because I’ve thought myself about where to put everything, and being able to allocate resources or see blind spots based on having a JD system with empty holes or potentially missing folders/notes in an empty ID that I know should exist. However, all these advantages have come to me as part of creating the Index and decidedly not maintaining the folder structure.
However, the question I want to ask is deeper. Why have nested folders at all? Instead of something like:
10-19 physical spaces
└ 11 home
╚ 11.01 living room
...
└ 12 office
╚ 12.01 filing cabinet
...
Why not just have a file system that looks like:
11.01 living room
11.02 bedroom
...
12.01 filing cabinet
12.02 central library
...
The only disadvantage I can think of is that as IDs get added the click-through browsability based on muscle memory of the JD maintainer gets weaker.
But this argument has two main limitations:
At the single JD category level this muscle memory issue may well exist anyway.
Not every JD ID will have a folder on every computer or technological boundary it crosses.
However, doing away with the whole notion of nesting folders confers many advantages:
In any system where one can see the flat folder structure it would be quite easy to see which IDs are missing.
Teaching people to build a JD system would now involve just creating folders without creating IDs to layout the basic needs the system needs to fulfill. This can then lead to instruction about how to group things based on similarity, goal, physical proximity or any categorization the individual maintainer can think of.
Reduces the number of keystrokes in every filesystem to reach a distal JD ID.
Reinforces the importance of an Index as the Index now becomes the canonical way of even understanding the system.
What does everyone think?
I personally stumbled on this idea when trying to use Syncthing to move folders across devices. I’m a bit annoyed having to type long file-paths and worrying if I hit a filesystem file-path length name every time I move files around. Z:\11.21 is automatically the shortest possible JD-compatible file path, so why not use it exactly as is?
I’ve thought about this a lot too. In fact I started out with categories as the top-most level when I was just starting out.
A few thoughts. I’m definitely with you on exploring this seriously, not criticising at all.
browsability and muscle memory may be most important for a single user, but you could also use a JD system in a multi-user setting. There, the discoverability becomes important; the workbook has a lot of anecdotes relating to this. For a newcomer to the system, being presented with up to one hundred folders in a flat list would be overwhelming; being presented with ten (well-named) folders to start with allows an easier initial choice to be made. This is a point made in the workbook too.
I think if you have a full-text, fuzzy search interface (like most wiki/note apps do), you don’t need the areas in day to day use. I do have the feeling that areas are important in the design phase; although there, too, perhaps that might not be the case.
One idea I had was to apply the areas as an attribute of the category folders instead of as a level in the hierarchy. For example: the tagging software tmsu creates a virtual filesystem with directories for tags and symbolic links inside them to the tagged files. If directories 10 through 19 were tagged with 10-19 Area 1, then you could see that grouping in the virtual filesystem if you wanted. The ‘underlying’ layout would be flat, which would then facilitate the syncing and interoperability issues you mention (thanks for that; I hadn’t considered those aspects yet).
What we need is a file manager/interface which can be configured to hide a certain level in the file tree …
I do that to an extent by configuring my ‘fuzzy find’ (fzf) to use the command find with -mindepth 2 which then only matches level 2 and hides the empty area directories from my results list.
BUT, this is all platform-specific. The 10 - 10 - 100 directory tree is the most univeral format which satisfies the ‘soft’ objectives of the JD system.
Very interested to hear further thoughts on this topic!
I run (some) Linux and Windows, but since work-world is Windows - I’m mainly focused there.
(I have no clue about Apple or iOS.)
Don’t know if it tickles your fancy, but I run Everything as a countermeasure for “excessive clickyness” with folders and navigation.
Settings:
Under “Tools” > “Options” > “Indexes” > NTFS" I have disabled it from looking on my system drive and other areas.
Under “Search” > “Add to filters” I’ve added the path to where my JD structure is - and made this filter always loaded under “Settings” > “General” > “Home”.
In other words; It ONLY looks in my JD structure.
Everything is blazing fast, and I just have to throw some letters in there to find / discriminate down to the folder I want.
Always at the ready, a click a way - in the taskbar.
Sidenote
I’ve seen “behind the scenes” of large, commercial operators that use file servers/shared network drives as their main storage and production systems. Yeah, they do have some internal rules and guidelines about how the folder structures should be - but since humans work there, it is not always so “clean” as it was intended. But they run Everything as a centralized resource from the IT department, where the filters and settings are done by the admins. That means; everyone there (can) use Everything to search/find what they are looking for. It’s quite efficient.
Interesting. To answer the question posed by the subject: ‘because it does’. That’s just how it happened at the time. (JD’s design is very accidental.)
When I used it in my work email, heavily and rigorously, I didn’t use area folders. I went straight to category, exactly for the less clicks reason. It worked great.
If it works for you, do it! But I think for most ‘normal people’ (i.e. people who probably aren’t on a forum nerding out about a decimal-based organisation system), the neat hierarchy is best.
What I like about it is that, once you’re ‘in’ an area, you should be able to totally forget about the others; cast them entirely from your mind. They’re not relevant to the thing you’re looking for. So if you can’t even see them, that should help.
That was how I immediately assumed it should be done when I read about taming email in the Workbook – only the Index needs the full hierarchy, everywhere else all you need is the AC.ID be it in a folder name, as a tag in your email program, or whatever.
And then if your index is one file or is a collection of notes which you can search-to-open (fzf or Everything or whatever), you kind of don’t see the areas most of the time.
@clappingcactus I’m interested in the technical reasons you alluded to, sync and interop with other tools. I’ve only skimmed the posts you linked to, yet. I don’t suppose that would be something that a JD Spec would help solve?
By the way this is really really enticing. On my site I have all short paths redirected to the full path, so I can just link to /21.01/ or whatever and that will expand out when the user clicks. It’s really really nice to be able to do that.
I’ve been thinking about this more. I think there’s this interesting tension between the usefulness of the tree structure for organising, and the usefulness of the flat structure for working faster.
It helped me tweak my own workflow a bit. I thought I’d share since it illustrates well how the tools you use can make all the difference.
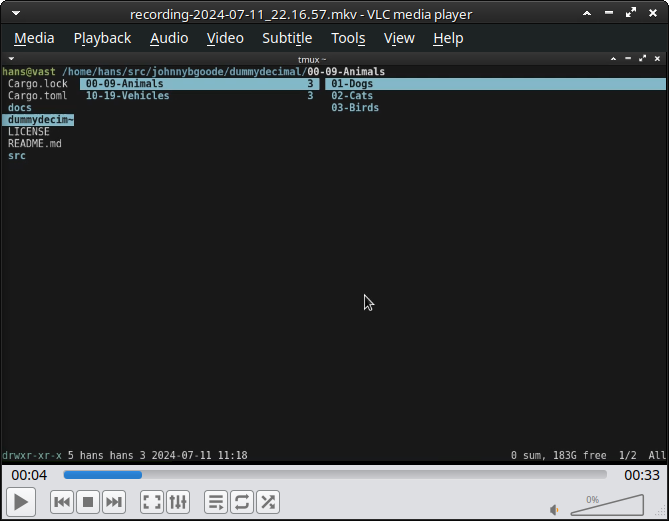
opening a JD tree in ranger, a multi-panel file browser.
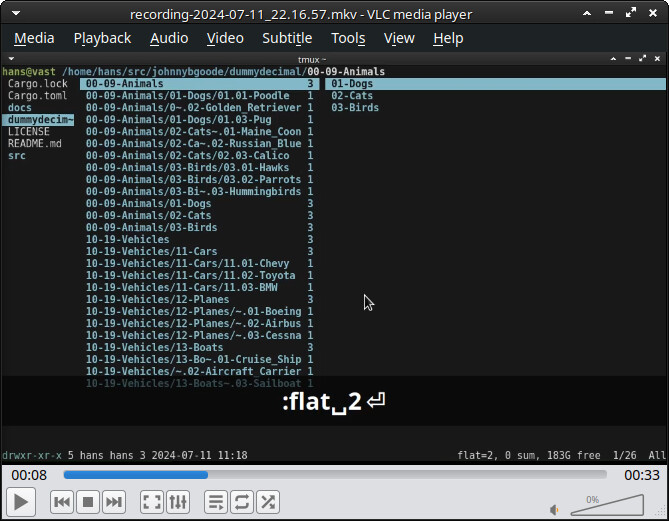
execute the command :flat 2 to unnest the tree to two levels. This shows all my IDs in one list. This is a useful place to be – I can search, sort by last modified, etc, and get work done.
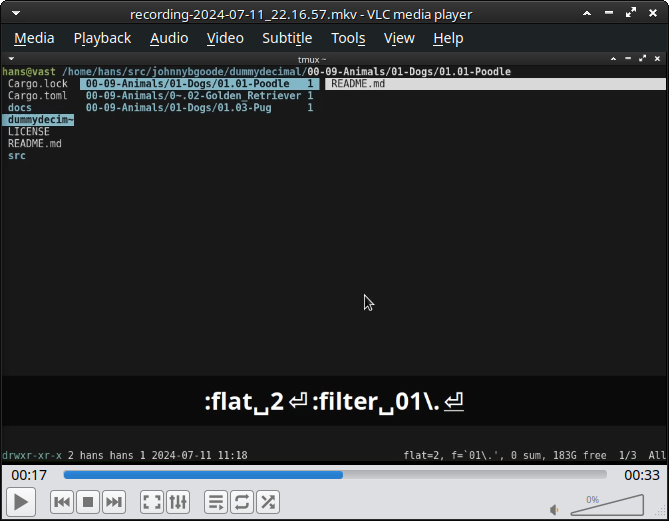
Now say I want to focus on one area. I execute the command :filter PATTERN to limit the entries in view: for example, :filter 01\. shows only IDs in category 01 Dogs.
The filter persists, I can browse the child directories, open files etc, until I run :filter with no arguments to reset it.
Here it is in one motion:
So that’s fairly niche, and there are things to improve (it would be nice to hide the reduntant parts of the folder paths in flat view, for instance), but I hope it makes clear that the proper tooling, you can get pretty much any view you want on a plain ol’ filesystem hierarchy.
And, of course, we could just as easily go the other way round: make everything flat on the filesystem (to your point about interoperability), and add hierarchy with tags, symbolic links, virtual groupings using our tooling. This is really appealing to me – but I worry that I’ll end up with something like how my Zotero collection is at the moment, where I have all kinds of tags and categories I’ve forgotten about, and just resort to the big list of everything even though it’s sometimes slow. This is what the JD nested structure helps avoid.
thanks Fellow Programmer @SwissArmyWrench for the dummydecimal folder tree!
This is awesome! I’ve never tried Ranger, but the siren’s song of the command line is leading me to move more and more of my workflows into the terminal, so I might just have to give it a try!
Good to know that the DummyDecimal tree is being helpful. I created it for Johnnybgoode because I realized it A) helps privacy and B) would reduce a lot of confusion if multiple people were working on it and trying to resolve problems.
I’m going to play devil’s advocate for a few points in the thread to make sure all thoughts are on the table. I’m not particularly wed to my thoughts, and I myself have not re-done my file system based on this thinking. Just shooting ideas around.
Two points to respond to here:
Yes I think that discoverability is less important for individual users and more important in multi-user settings. For sure. But my take is that the biggest advantage of the system is to create a coherent address or location, not a path. If JD was a system to create the most sensible path to something we can just reduce it down to using some sort of alphabetical or chronological listing of files, with a pseudo-tag filetree that way every file is reachable from every location in a few clicks. This is obviously an extreme point to make, but I want to highlight that I think the strength of JD is in clarity about the system, and the ability to use the index for decision making, not the file-system. See the post below about using Everything to find things. You anyway wouldn’t want 20 users spending time browsing files as that adds up to man hours over years. You’d just come up with a fzf or file-naming scheme that’s standard across use-cases.
Optimizing the system for newcomers doesn’t have to happen at the file-system level, and should not saddle the system with a permanent design decision that was most helpful at the beginning of the organizational steps. I believe that newcomers also struggle with “too many areas” or “too many categories” syndrome. See: problems like the freelancer, or academic. It’s possible that doing away with a file-tree structure allows us to say “take all folders out of their current locations, no nesting allowed when beginning the process, now count your folders, now create the broadest possible folder category that encompasses most folders in your system and call that category 10-19.” This kind of education eases ramping on, naturally forces the maintainer to think as broadly as possible, and can hierarchially organize a user’s personal interests according to historical track-record. This is not what I suggest, but is an off-the-cuff example of the kind of JD development possible if we stop thinking in a file-tree first frame of reference.
Woah, I didn’t know that Everything can be limited in its search index. That’s awesome. But I think my point wasn’t necessarily about reducing clicks. It’s just more “what would the JD system and method look like if we didn’t actually put folders in folders”. That kind of idea would change how the system is designed, built, maintained, taught, used etc. Yes “Everything” the software absolutely solves the “used” part of my previous sentence. But I’m wondering what advantage JD would give to the average person, if they focused on “file storage clarification” rather than “folder storage design”.
That’s something I hadn’t considered. It of course helps to be “zeroed-in” on a topic. But that might still be equally effective working from ones index or notes rather than ones file-system right?
I think this begs the question of people in this thread: how many times do any of us perform a file-search-first action in our day to day lives? I find that for me as an academic, the answer is not much. Files are an endpoint, kind of like a game-save-state situation. If I need to cross-reference them, I already know where to look thanks to JD helping me organize at the outset. If I don’t know where to look, just like in the physical world, I’d check my notes first. But that comes from me being immersed in a note-first professional world.
So, it’s really boring. I stumbled on this idea because I use Syncthing to synchronize a set of JD areas. For me 10-19 is knowledge, 20-29 is projects, 30-39 is physical spaces. These three areas are always synchronized across all my devices. I then created a new ID elsewhere in the system, specifically 46.19 for “portable software” that’s supposed to live on a USB-stick. I realized I would want 46.19 on my laptop since there’s no point duplicating software if I have a portable version of it fulfilling the same function. To synchronize 46.19 I would then have to set up a shared folder in Syncthing from my NAS for all for 40-49 and include only 46.19, or I would have to synchronize 46.19 directly to my laptop and there create two folder hierarchies just to contain one new folder. Either way, there’s an unnecessary organizational tax and mess done on either the NAS side or laptop side.
Then it dawned on me that the same logic applies to all my files and folders. If I just had a flat folder ID structure, then the problem disappears, and on every device I only synchronize the IDs that that device needs, with exclusions and inclusions being handled at the syncing level. Not at the folder creation level.
It’s as if I’m dealing with my notes, I don’t really create a bunch of unnecessary folders to house a single note. I just write the note, reference it across the day, and if it’s relevant to a topic I make note in that specific topic that a new relevant note has been added to my notebook about it. Why handle files differently?
Absolutely true for me, too. I’m a mess myself. Just using JD to be less of a mess. I’m against tags (another topic). Except … that’s secretly what JD is right? Like Karl Voit would tell us all to “create a list of finite tags and apply as few as possible for each file”. And a JD system in effect forces the maintainer to work with a list of finite tags (at most 100) and assign as few as possible to each folder/project (1). It again comes back to the point that for me, someone who’s used my JD system since around late 2021, the biggest advantage has come from clarity about my system, and not from the folders. I have created knowledge of the files I like to store, and routines for how to store them and how to retrieve them. But now, at the point where I’ve memorized my IDs, it’s less important to remember with every single operation that 10-19 is knowledge.
@clappingcactus , I for one am enjoying this discussion immensely. Great food for thought. My initial response was also kindof meant to play the devil’s advocate. I might try to keep arguing the other side – insofar as that exists here – to keep deepening the discussion.
However, this weekend is really full for me. So I’ll just mention a few things I can touch on briefly:
Intriguing distinction – to me – between the most coherent address versus most sensible path. I would think that the location is the path – that’s how it works at the neuronal level, as far as I understand it, and also how it works in an interlinked corpus with hyperlinks. Also, I would say the hierarchical folder system actually is the best way to make a sensible path to something. The guarantee about max two levels of depth, the use of decimal numbers instead of alphabetic sorting to ensure things stay in one place, for example. However:
Yes, yes, that resonates very much and sounds like a template for a way forward! I just think the original JD directory tree is a really good ‘poor man’s’ or ‘low tech’ index in itself, for people who don’t know how to set up some of the additional tooling layers that have been brought up.
I sometimes notice how, ironically, the process of thinking through were things belong has made their titles so memorable that I can just jump straight to them with a fuzzy search (without having to use the numerical ID[1]).
I use Syncthing too and I was planning on doing this at least at the category level. Maybe sync a few areas where I know beforehand if I know they will definitely belong on all devices. Have you noticed any performance issues if Syncthing is handling tens or hundreds of directories? Have you used the .stignore file at all? It works for keeping stuff off certain devices, but it is obviously not at all secure if you don’t trust those devices fully, and I thought there were a few cases where performance could be a problem.
Thanks for the Karl Voit mention! Great stuff!
I try to always, after finding my target by title, erase my query and type the ID, just as a matter of discipline to get the numbers in my head … ↩︎
@SwissArmyWrench@johnnydecimal ranger has definitely been growing on me. File and even image previews are awesome (a bit finicky to get set up) and after I’ve added a few custom commands (like integrating fzf) it gets better and better.
In fact, I modified the cool built-in :bulkrename command as a way to batch file things into their JD ID directories from the inbox.
select a few files and run :jdmv – the list of files is opened in my text editor.
add the AC.ID at the front of the filename – with autocomplete because this is my main editor with an fzf/find powered completion source
close the editor, and not only are the files renamed, but my script finds the corresponding directory and moves the files there.
FYI;
I’ve been using Syncthing for a couple of years.
My experience
very stable
don’t overdo it with folders / structure (it’ll become tedious and you’ll redo it later )
Things I want synced to multiple locations / devices live in my 9* area of JD
Single means only one generation / 1 copy
Multi means multiple generations with autocleanup / versioned backups back in time
They all share 1 common shared folder that does two way sync, if I wanna “drop something between devices”
I use a Synology NAS running DSM 7 as my “main” device - seen and synced with all devices. The others are paired/linked based on necessity.
I use Synology Hyper Backup to selectivly pull / create scheduled backups from other JD folders.
I use Synology Cloud Sync to upload encrypted backups to (free) Google Drive and/or OneDrive accounts for stuff I want to have off-site as well.
I use rsync service to schedule and transfer folders/files between Synology NAS devices (reason is I have a couple of old Synology NAS servers that does not play well with latest software, but rsync has been around for a long time and works great)
Inspired by the thread Split ID Folder;
and inspired by the use of ‘ Heading IDs’ in the Life Admin Quick Start Pack;
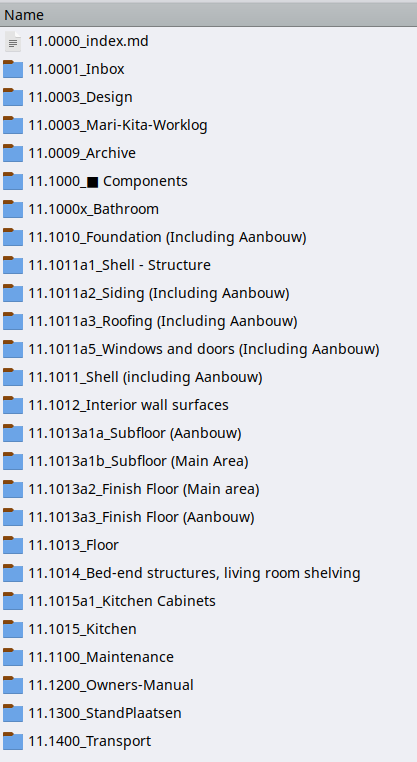
and realizing I hadn’t organised my house components yet because I couldn’t think of how to map a very deep hierarchy into a preferrably shallow JD system;
I thought I would try to follow my own suggestion.
60% chance I’ll deeply, deeply regret this, and move it all to its own more suited system.
But I figure I might as well try for a week or so
What is this??
I’m lengthening the IDs to create a hierarchy without putting this in subfolders. It requires some trickery, but if you alternate numerals and letters, things stay in the correct order. motivation: I prefer search/filter over clicking into sufolders.
Why?
I was reflecting on what @johnnydecimal said in his last video about how ID’s have grown bigger over the last decade, so subfolders are more justified now. I was thinking how this makes the ‘jump’ from level to level bigger (or smaller?). In any case, it feels like it makes it harder to know whether to make something a category or an ID …
So I thought: what if you could make it more of a sliding scale, without adding more folder levels. Maybe you could do this with Categories, too (in front of the decimal point).
Doesn’t it break the max-100-IDs rule??
Yes, it does. However, I feel like it kind-of doesn’t, because these are clearly defined as sub-ID’s of something. After the House Components (.1000, so really just .10 lengthened), the list continues with 1100_Maintenance.
How would this generalize?
My current thought is that if you ever came to the conclusion that you really needed to expand an ID into a kind of sub-ID like this, you would take your ID (e.g. 10 House Components) and rename it with more zeros, and maybe put a '301 moved permanently` record inside it, and split its contents up between new sub-IDs.
Downsides
To keep things sorting in the desired order, all the IDs have to at least the same number of numerals before the first letter or punctuation sign. (like 0001_Index). That’s silly because then you have to predict how deep you’ll go … but it’s not hard to left-pad later if necessary (if your setup can handle directory name changes). The alternative is to live with the shorter IDs coming before the longer ones.
(also, spot the problem with the ‘Floor’ section. ranger sorts 11.1013_Floor before 11.1013a1a_Subfloor, but thunar does NOT.)
Great thread! Good observation on the differences in what counts as an ideal view for planning/tweaking your JD system vs using it in single or multi-user settings.
Also, two comments on tools. First, with Everything, you can create filters that you can toggle with a hotkey, so I have one for JD, and I can use Everything for normal search or as a JD search. Second, Ranger does look great, but for those of us that might want a more familiar UI and more functions, I want to mention Directory Opus (https://www.gpsoft.com.au/). It’s not free, or even cheap, but I’ve used it for many years and it can do almost anything you’d want. It can quickly switch between a folder view, a folder/file tree view, a “flat view” (all files in the folder and all subfolders shown at once), and almost any other view you can think of. You can program your own functions if you want and the devs are super-responsive on the forums. Sorry for the advert, I have no affiliation, just wanted to let others who might share my strong desire for customization and keyboard efficiency know about it.
A follow-up on my experiment, since it’s been a week now.
My findings are that this could work in certain situations, but one shouldn’t expect it to be a magic ‘upgrade’ that suddenly gives you lots of flexibility while keeping the benefits of Decimal pre-ordained structure. There’s too many ways to shoot yourself in the foot. And it makes you think about the order of IDs too much, when I do believe those should be there as unique IDs but not be part of your name for the thing.
Another area where I thought something like this would be handy, was in my code category. I had one category for all coding projects. Then I thought it would be useful to differentiate between ‘my code’ (where it’s mostly my work, by myself) and ‘collaborations’, where I am working together with someone or contributing to someone else’s project. I already had three decimal places in this category, anticipating putting a lot more than 100 IDs in there; now if I would start “other’s code” at 200, say, that only gives me 100 IDs for ‘my code’ which won’t be enough. Knowing this, I could choose to ‘infill’ the IDs as necessary with alternating num-letter-num-letter.
Is it a problem that this suggests things are related when they aren’t?
42.0145 client project nr. 32
42.0145b some little tool I made <-- added later, should sort before 42.0200
42.0200 ⬛ Other's code
I know I said above that the ID shouldn’t matter, it’s just an ID … so maybe this would work … As you can tell, I’m still on the fence, and that means there isn’t a compelling reason to do something like this.
(except that I stubbornly want to keep all ‘code’ in one category, rather than creating a new category for “other’s code”)
Conclusion for now:
sometimes we know we’ll need more than 100 IDs, e.g. Johnny has given himself space to write 9999 blog posts. In that case – when you know you need to expand – it might in certain cases also be helpful to think about some hierarchy if you need it. In my original case of house components, you could encode a natural hierarchy in your IDs. It comes down to whether something like that should just be one ID in Johnny Decimal. Anyone have any thoughts on that?
Might this be a case — I find them to be common — where you are massively underestimating how many things 10,000 things is?
Because that’s how many things a 42.0000 scheme can handle. Ten thousand! Same as the creative pattern. Same as my blog posts.
Say you create one client project or little tool every day. Including weekends and holidays. Come talk to me just before Christmas 2051. You’ll just have run out of IDs. If you only create stuff on weekdays that pushes us out to December 2062. I’ll be 86.
This is why a four-digit extension is useful in these situations. You’ll never run out. Not in any meaningful timescale.
100,000 is probably far too many, and 5 digits is unwieldy. 1,000 might possibly not be enough. 10,000 — 4 digits — is the sweet spot.
So just split at .5000. Above that is other’s code. Below that is yours.