Not being an Obsidian user — I’ll correct that soon, it’s clear I need to understand it — I’m not sure this question is clear to me, sorry.
Here’s the intent of the index. How you implement this with various software may vary; such implementation details are not so important.
Your JD system is made up of a bunch of stuff: files, notes, emails, data in apps, websites, physical objects. All the things.
What we need to avoid is a situation where you (not you; the royal ‘you’) use your file system to allocate JD IDs. The good stuff here is in the workbook, lemme extract it.
workbook extract
51.03 Case study 1: Organising travel
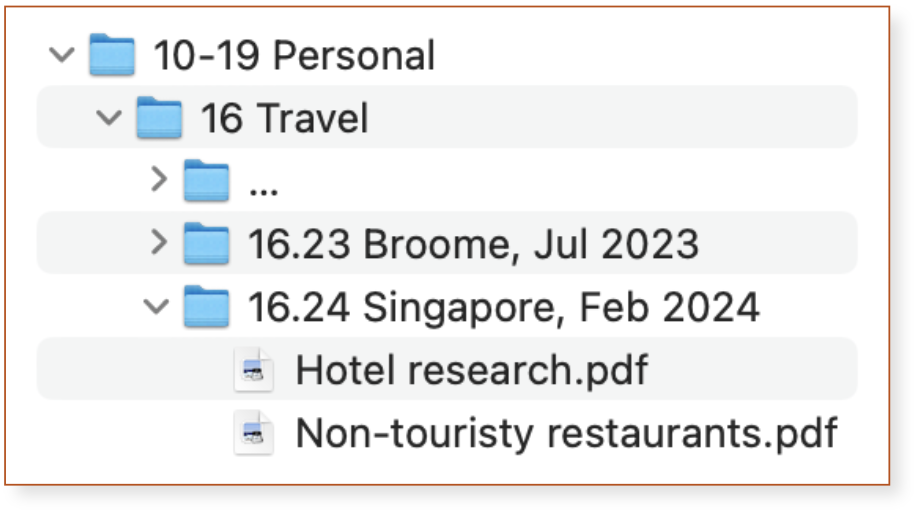
You’re planning a holiday, and part of your research involves downloading brochures.
Of course you want to save them somewhere, so in your Travel category you create a new folder, assign the next available number, and start saving the PDFs that you download.
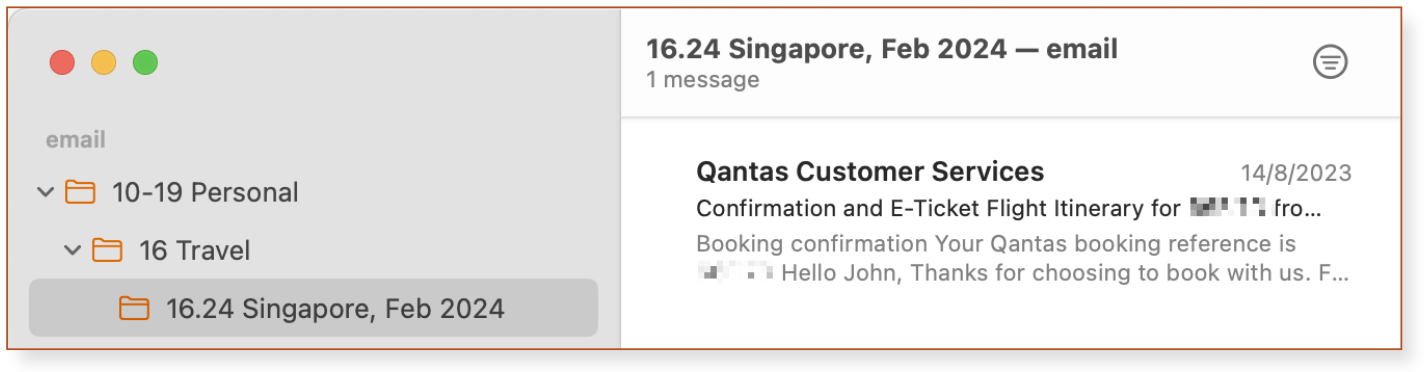
Later, you book the Singapore trip and want to save the email confirmation from the airline. You’ve already got an ID – 16.24 – so you create an email folder with that number and move the message there.
So far so good: you get a gold star.
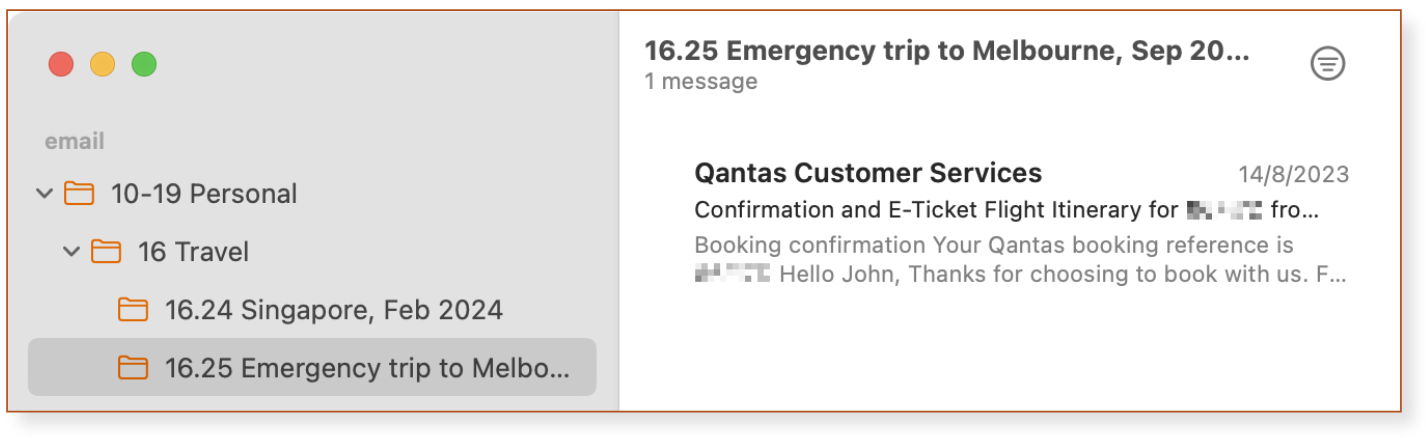
Next, an impromptu trip interstate comes up. Family emergency, last minute. The only artefact that exists is the email confirmation and, by now giddy with the power that comes from being organised, you create a new folder in your email in which to save it.
The next number is obviously 16.25, so you use that and get on with life.
Here’s the situation.
The next trip
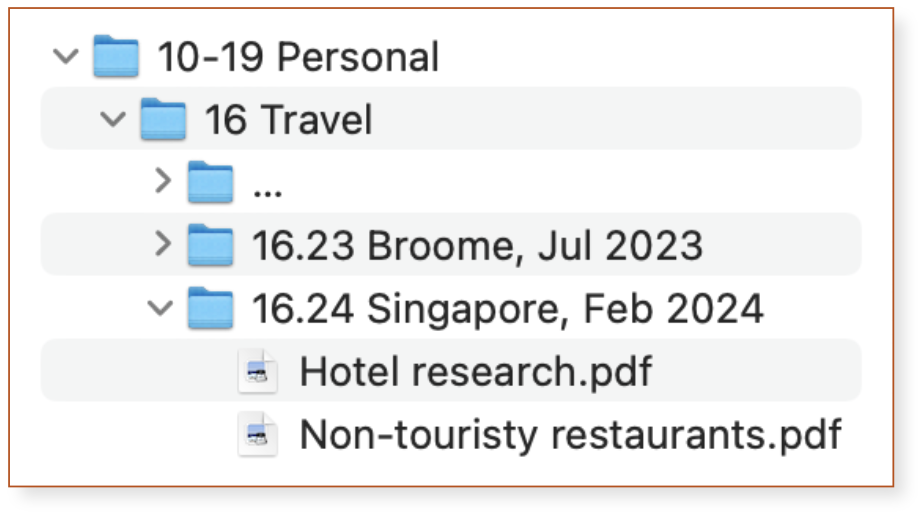
Singapore was great and you decide to spend more time in Southeast Asia.
You start researching a holiday to Vietnam. You’re downloading PDFs again, so you jump in to your file system to create a folder, and what do you do?
Now, reading this you’re slapping your head and telling me that of course you wouldn’t be so stupid to do this. Of course you somehow remember that you’ve already used 16.25 for that quick trip interstate, and of course you’ll use 16.26 for the Vietnam holiday.
/ends workbook extract
So you must implement an index somewhere. If you use Obsidian, it’s probably going to be in Obsidian.
Now, because of the nature of Obsidian, this index implementation may overlap with your file system. If Obsidian’s sidebar shows you a representation of the files on your file system, this might already do a bunch of the work for you. For example if it shows you your area and category folders, then there’s no need to recreate them somehow with an Obsidian note.
The key is that when you track an item that isn’t in Obsidian — an email, say — then you must first create that ID as an index entry in Obsidian. That’s how you generate the new JD ID for the email: you do it in Obsidian.
The note might be mostly blank: I’d just use it to tell myself, hey, this thing you’re looking for? It’s not here. It’s in your email.
Does that help clarify? There’s a ton more information in the workbook; we dedicate an entire area to the index.