Continuing the discussion from Extend-the-end + vs. 01, 02:
The Problem
Recently, I ran into the same issue that @johnnydecimal described above. I’ve been indexing devices and their associated accounts using sub-IDs, like so:
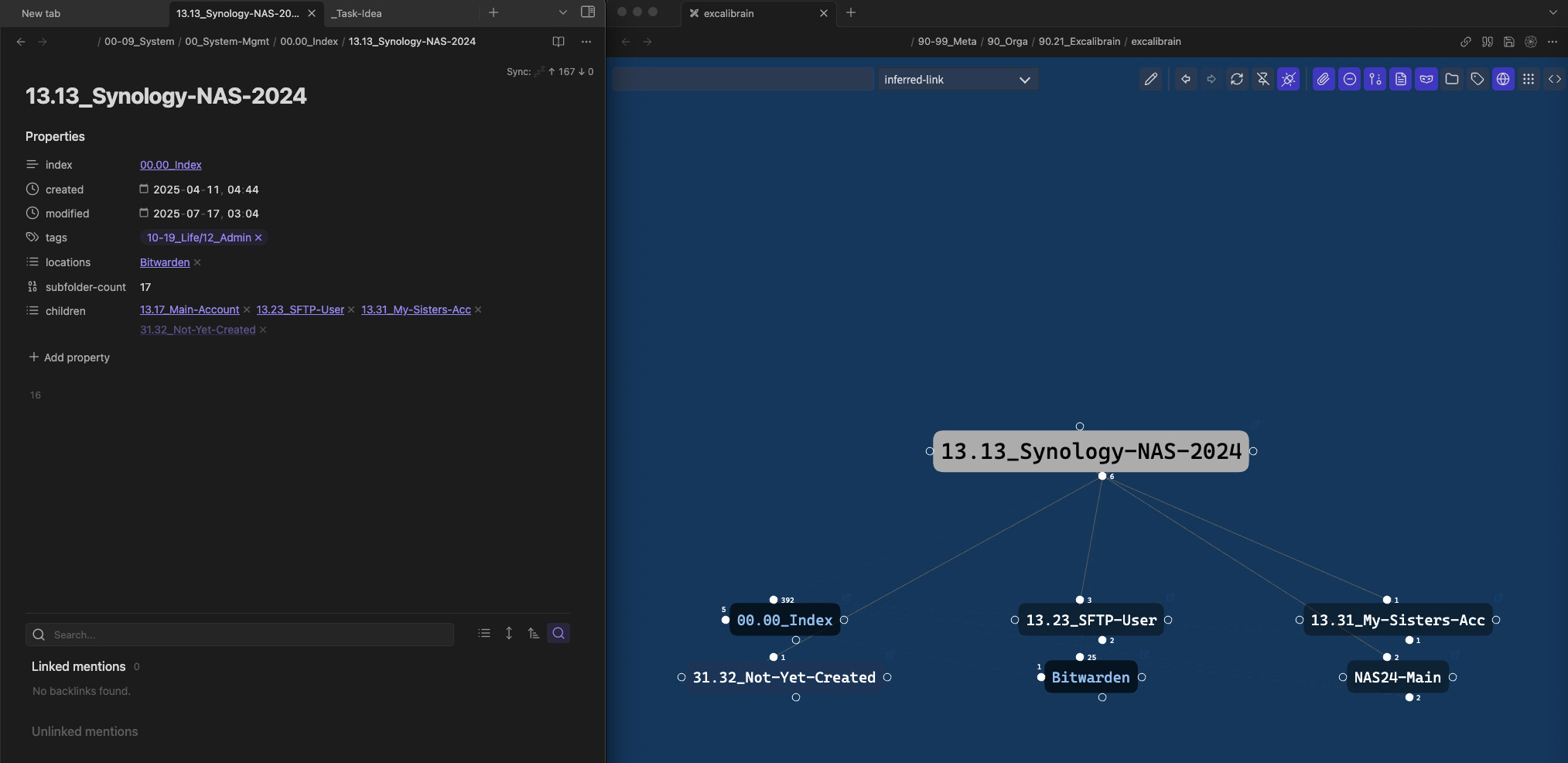
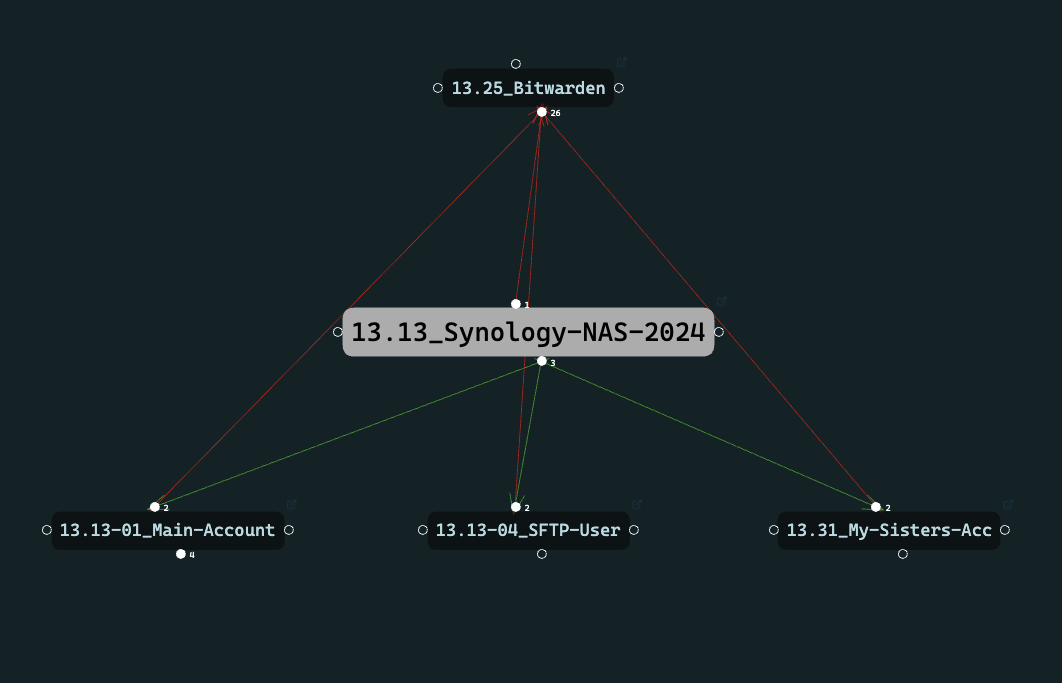
13.13NAS13.13+01Main Account13.13+02My Sister’s Account- …
13.13+11SFTP User
But when I want to add a sub-note to one of those, e.g. 13.13+01 Main Account, I hit the same wall:
13.13+01+ More Stuff
The solution we previously came up with was to reassign the child note its own main ID, like this:
13.17 Main Account
to get
13.17+ More Stuff
But that approach bothers me now, for three reasons:
- I want all related accounts to stay together, so I don’t accidentally overlook one.
- Accounts are children of devices.
Main Accountis a child ofNAS, and I want that relationship to be reflected in the structure somehow. - Any child could eventually become a parent of another note, forcing me to reindex.
A Different Approach: MOCs (Maps of Content)
To avoid these issues entirely, I’m considering dropping sub-IDs in favour of something more flexible, but just as powerful.
The idea:
I create a parent note.
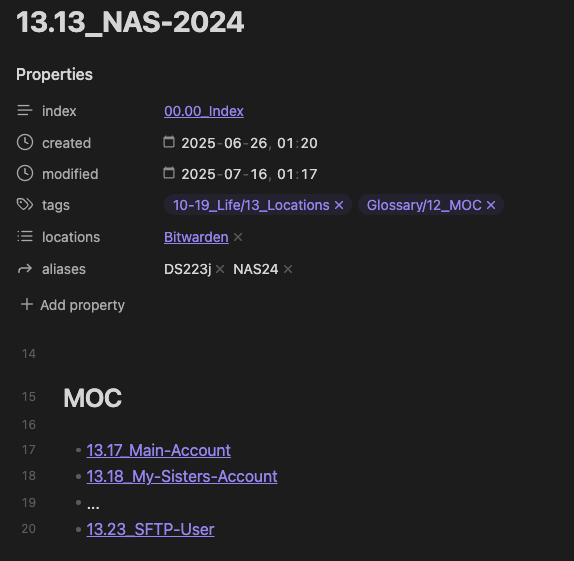
And all the child notes are simply linked or referenced inside this parent note. That gives me a clear parent–child relationship without the fragility of sub-IDs. The structure remains flat while depth is now handled through flexible linking.
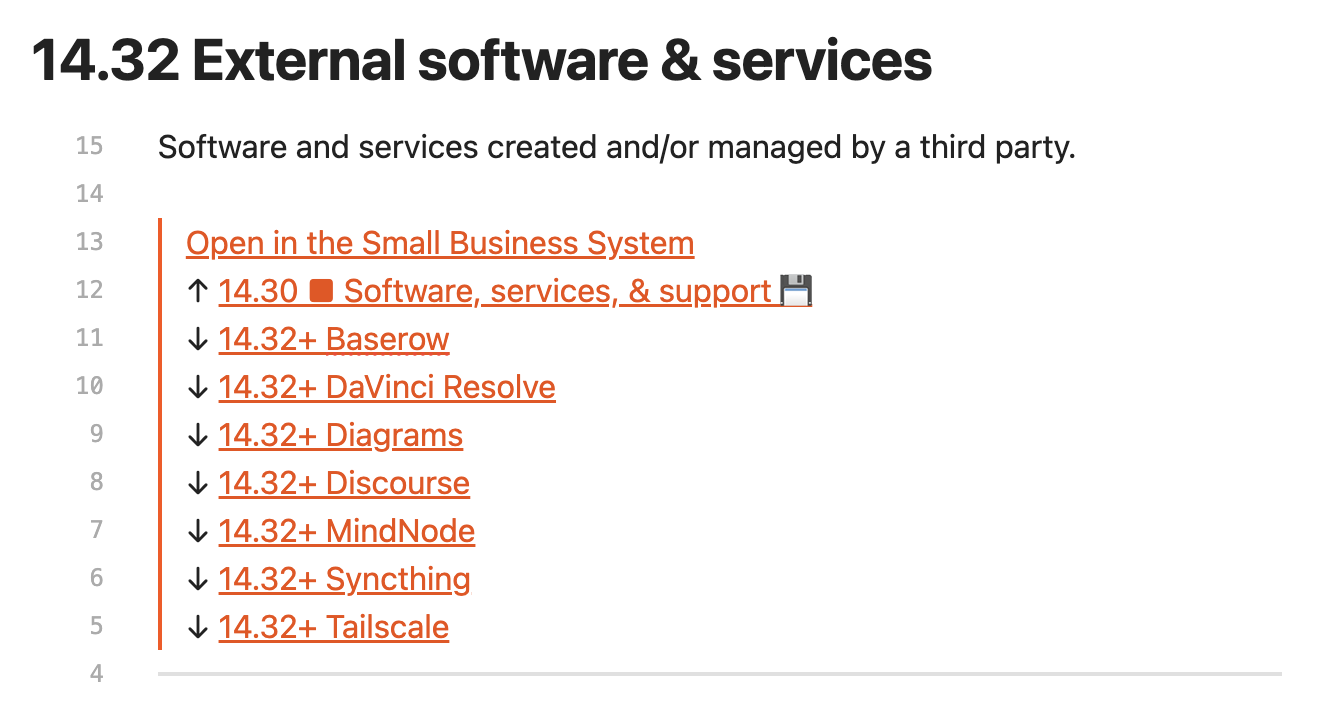
So, if one day I want to add a child note to 13.23_SFTP-User—say, “Stuff about SFTP”—I just create a new note like:
13.27_Stuff-About-SFTP
…and link it inside 13.23_SFTP-User.
No need to re-index. No confusion about where things are. Infinite depth, if I want it, achieved via linking, while following standard AC.ID_Title JDex format.
Sub-Notes
In this scenario, + only serves to divide a longer note into smaller notes. This is for structural purposes and does not imply any commitment to a parent-child-relationship
Beyond 100 Items
To quote the example use case on the JD website:
If you create more than 100 blog posts, then instead of using something like 22.00+0000, you use 22.0000.
Not all of those (potentially 10,000) items might be blog posts, some could be related child notes with their own JDex. If you need a clean overview of blog posts only, simply link each blog post ID into 22.0000.
Grow As You Go
If the MOC note 22.0000 should ever become too long, you could either split it into sub-notes using 22.0000+, or assign those parts their own JDex and link them into a new unifying MOC note. There’s really no limitation when it comes to MOCs.