I will make several posts to share my steps, my views, my system and my feed-back.
Why moving from PARA to J.D ?
I discovered PARA last year in a video tutorial together with J.D and was appealed by the split Project / Areas of responsability / Ressources /Archives. J.D which I did not investigate enough was just a numbering system, so I concluded (yes I am guilty for being lazy and it costed me 1 year of pain…).
In very short, when adding a file, you scan from Project to Archive until you find a best place based on criteria given by Tiago Forte.
These 4 categories well suited my mental organization so I had thought . So I deployed this organization both on my work PC and my home PC.
After a short time using this system on home PC, I realized that opening Project or Area folders is a pain so I moved the sub folders to the top. I created empty folder 10 and 20 to have separators between categories.
Then I add a Customization folder for my applications in order to ease the my backups.
Second issues, I transferred the initial “mess” prior to PARA into 4 smaller “messes” in each category. Then I tried to improve this with better organization but a new issue soon appeared: a project involving Python programming would require Python ressources (tutorials, examples, references whatever necessary materials) and a look to old programs in Archives. So I had to navigate through the whole 4 branches.
In conclusion my “mess” was cleaner than before but less efficient for me ! I needed a more horizontal folder structure for my files.
Then I investigated deeper J.D, bought the book to get thorough explanations and prepared the switch to J.D system.
In next post, I will cover the deployment of my J.D system on work PC.
I translated and summarized the back bone as follows :
00-09 Système
01 Customization
this holds my HTML shortcut board to many web applications at work, password manager, Office365 toolbars and setup, and other configuration files for application.
02 Templates
PowerPoint, generic planning backbone, synthesis dashboard for a project, test notes
03 Inbox
Stuff needing later reading and/or later sorting
10-19 My current project
I will work approx 2 years on it. Then it will move to 70, without changing the structure so J.D 3-folder-structure will not be met but it is ok for me. Only a copy of company centralized data are there. Why not an archive here ? Because these archive would weigh ~ 70% of all my data and I cannot do backups on such bulky data.
20-29 My department
20 Archives
My 2 previous departments (different jobs). I followed the excellent advice from Johnny: why moving to a special Archive place ? This way I do not need to recreate a structure as in PARA model. It already exists and I will be familiar with it, I know straight away where the stuff is.
21 Paperwork
Including health insurance and billing.
22 Annual review with my boss
There is no ID there, since I had a folder per year.
23 Business trips
24 Company procedures
Daily procedures that I need to follow.
25 Trainings
My trainings, my trainees, training material for myself or my trainees.
30-39 Company other than my department
31 Organization
Organigrams
32 My site
How to access for visitors, lab capabilities, etc.
33 Other sites
Lab capabilities
34 Company procedures
Other than my department procedures
40-49 IT stuff
41 Standard applications
Office365, Windows, etc.
42 Company PLM
Info, tips
43 My daily applications
44 Code stuff
Code tutorials, reference manuals, etc.
45 My scripts
I code a bit with Python script to process test data
50-59 Métier (know-how)
51 my tools
Excel processing tools
52 Generic method for work
Notes, courses on efficiency at work, problem solving, etc. There is J.D book there :-)
53 Engineering
Mainly Finite Elements courses or other mechanical engineering materials
54 Company test methods
55 Simulations
Guidelines, correlation, codes, method developed internally
56 Automotive regulations
60-69 Personnal
Almost empty. Given the size, it should be one or 2 IDs but they would be nested in an AC totally irrelevant for me.
70-79 Backups / Archives
70 Former projects
71 Snapshots of some of my OneDrive data
Why making backups on cloud synchronized data ? Because I sometimes mess up files writing stupid things in them and saving to discover days, weeks, months after my mistakes. Content is areas from 0 to 5.
There will be links which are not implemented yet.
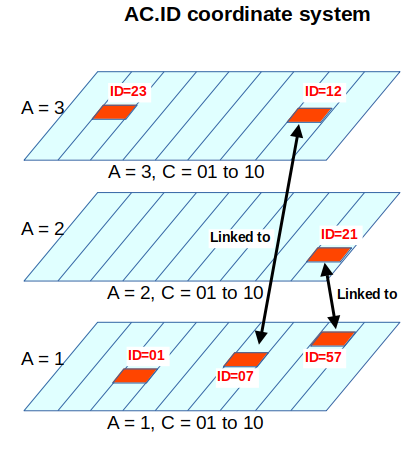
J.D is two-dimensional as I see it in a geometrical world: AC.ID → A would be X and C would be Y. So you have a stack of layers defined by AC supporting clusters of atomic data which are ID.
When 2 topics are somewhat related, you no longer have to jump to A then C then the ID, you can “enter” by another AC.ID linked to you destination in your index.
This eases the decision between putting a given ID in one category or another since both are linked.
Then there is 2 (or more) entry points to access to topics closely related which should increase my productivity. I quite often mix similar topics or locations for stuff (both on my PC or in my flat) so this gives me gives more chances to quickly find them.
If you note system supports links (as hypertext) then it is even faster. OneNote does support this.
It took me 6 weeks to classify the data (read clean the mess in my previous deep folder structure). Areas are capitalized.
Here is the outcome with a pincée of PARA as follows :
10s area is a big & long term project. Former PARA Project. This at the top as it is often accessed. As I have huge documentation, 10 areas are not enough. So I have 9 super areas numbered with 1 digit so the numbering is 11.3.05.23 for example.
20s area holds smaller projects. Former PARA Areas. Quite often accessed.
Where it is relevant, I had archive category or archive index with 0 so that it shows at the top of the list.
The following extract is summarized and translated into English.
00-09_SYSTEM
01_Customization
This holds password manager, linux config, filezilla parameters, application parameters to be copied to home directory after OS installation.
02_Templates
Templates for Libreoffice documents and technical drawing
03_Inbox
Documents to read later and classified
04_My_J.D
My Zim notebooks hosting the J.D index and notes
10-19_MAIN_PROGRAM
20-19_PROJECTS
21_Bash_scripts
Backup scripts
22_Python_scripts
23_Knowledge_repositories
My HMTL documentation/notes hosted on gitlab. It covers : HTML, GIT, Vim, Python
30-39_AVIATION
21_Flying
Everything I need to fly: computation, weather, regulations, tips, personal tools.
32_Club1
33_Club2
34_Association1
35_Association2
36_Association3
40-49_ENGINEERING
41_LibreCAD
41.01_Documentation
41.02_Wiki
41.03_How_to
42_FreeCAD
42.01_Documentation
42.02_Examples
42.03_Tips
42.xx
My drawings
43_CalculiX
43.01_Installation
43.02_Setup
43.03_Tutorials
43.04_My_examples
44_Gmsh
44.01_Documentation
44.02_My_examples
45_Mystran
46_Z88
47_CAE_informations
Generic information related to CAE softwares
48_Other_tools
50-59_Computer
51_Linux
51.01_Bash_info
51.02_Linux_forums
51.03_Xubuntu_specific
51.04_Passwords
51.05_Licences
52_Office
52.01_Excel
52.02_Excel_VBA
52.03_LibreOffice_Base
52.04_LibreOffice_Basic
52.05_LibreOffice_Calc
52.06_LibreOffice_Draw
52.07_LibreOffice_Impress
52.08_LibreOffice_Math
52.09_LibreOffice_Writer
53_Programming
Mainly python documents
54_Calculators
Documentation on several HP calculators
55_Backups
55.01_DVD_listings
55.02_My_linux_setup
55.03_Short_term_backups
56_Tools
56.01_Keepass
56.02_Freeplane
56.03_GanttProject
56.04_Dar
57_Documentation_writing
Tips to write documentation including reStructured Text
58_Hardware
Purchased items, drivers, documenation
60-69_Daily_life
60_Archives
61_House
Buy, rent, insurance, devices, etc...
62_Health
Dental, glasses, analysis, covid, etc.
63_Transports
Bus, car, train
64_Taxes
Classified only by year
65_Banks
66_Work
Regulation, my company, job search, etc.
67_Purchased_goods
House, car, flight, cooking, medecinal, workshop
68_Recurring_payments
Phone, water, energy, cloud
69_Personal
Friend and family
70_PERSONAL_DEVELOPMENT
71_Getting_organised
71.01_PARA
71.02_Johnny.Decimal !!!!!!!!
72_Efficiency
72.01_Learning
72.02_Deep_work
72.03_Freemind_office_tips
Focus on tools
72.04_Methodology
Problem solving tools
73_Harmony_culture
73.01_Misc
73.02_VIA_strengths
80-89_MISC
81_Technical
82_Mails
83_Student_trainings
84_workshop
85_Entertainment
86_Cooking
I ran into the same debate/thinking what is an ID. I will share 2 thoughts and one suggestion :
Thought 1 : although I am not a developer I ran into the same question on a commit for a pull request I make on github for a software documentation. The answer from the maintainer : the commit is the smallest set of modifications which makes sense together. It means, if I remove one modification from the commit then the idea / purpose of the commit is less clear or does not make sense. My approach to ID is the same.
Consequence: I can have either 1 file in one ID or dozens of files even with 1 level of sub-folders. Analogy: take a bunch of grapes and 1 orange. If I have to classify this in a physical J.D system in the scope of my home, I would put them in Fruits category (in reality my fruit shelf) and one ID (in reality 1 box) for the bunch of grapes and another box for the orange. Wait, the bunch of grapes has 30 grapes in it and the orange has 10 wedges. Shouldn’t we get one box for each grape and one box for each orange wedge ? We could do it but it does not mean we should do it… I would put the bunch of grapes in one box even though each grape is unique, but they are ALL of the grape type. Same for wedges. Grape and orange are 2 different types of fruit so they deserve 2 different IDs.
Thought 2: I no more ask my self (or Johnny) what an ID should be. I ask myself : what do I want an ID to be ? I try to be consistent in my approach for my whole system BUT I do not apply exactly the same procedure / logic to each category. Some categories feel better with large IDs having dozens of file whereas others have 1 file !
Analogy: if I lack boxes I will but the bunch of grapes with the orange rather than with the meat in the fridge ! Why ? Because it seems more logical to me. One could argue to put the orange with the carrot since both are of orange color. Not my logic but if it works for you then go for it. The good place for stuff is where you naturally tend to search for them.
Suggestion : investigate Johnny’s standard proposals depending on the scope of data you want to manage. Give a thought and project yourself (by the thinking) into that system. Sleep over it. Give it a thought. Sleep again if necessary.
If you feel it is not right, change for another standard or a mix of several standards. Also have a look to other people’s system and take some inspiration of their systems. I believe each personal system should be different because each brain is organized differently.
Tough part : how much granularity should I have ? I believe there is no definite answer: it is a trade-off between what you need to get BETTER organized, what you can afford (1000 IDs) and what feels natural to be EFFICIENT when accessing to the file. This is entirely your call. Even though Johnny and others can be a good inspiration !
Final thought: some categories and IDs of my project will change in the coming years. Depending on how much more data I will have, I am ready to tune locally my J.D system. Daily life categories will not change much because my life will change far less than my project…