JD newbie here… I’ve had a trial run organizing files at work and it’s going well so far. So well, in fact, that I’m more excited about doing it for my personal life as well (I keep the two very separate).
I’ve read all the website pages about notes and emails… my question is about the practical implementation of that.
For work it’s easy: clearly-defined projects, plus things that fall outside of projects but can easily be categorised. Emails and notes nearly always relate to something in my folder structure so I can easily apply the JD numbers there as well.
For my personal life I also have some obvious categories and projects, but I also have a ton of random notes and ephemeral stuff that only exists as notes, emails, bookmarks, whatever. If I think about including those in my structure, I need to look beyond what’s in my existing file structure.
Seems like I have three options:
Build my JD system to accommodate my existing files. If I have a note or email that relates: great, number it too, but otherwise manage those as I always have with tags and keyword searches.
Build my JD system to accommodate both files and things that live only in emails/notes, and accept that there will be gaps in my folder numbers for things that only live in notes/email. Use a well-defined index to figure out what is where.
Stop using my notes app as an everything bucket and make more of an effort to save things in my JD filesystem where appropriate. The aim would then be to have my notes functioning more as described on the ‘keeping notes’ page, for short, supplementary information.
How are others managing this? Or is it a meta problem of my own creation?
If you have a well-oiled system for taking notes, I wouldn’t change it other than perhaps adding a JD number to the note title. If you think it’ll help.
If I want to do that in a non-disruptive way I’ll generally do it in square brackets at the end:
Title of my really great note [23.03]
This post might help with the ‘where to store these things’ question.
Your option 2. is where I’d be leaning. Use each technology for what it’s good at, and use my system to know where all the things are.
I would lean towards option 2 as well. I believe this is exactly why JD has to have an index! If everything was in your folder files, you wouldn’t need an index, but you’d also not be able to include half of the things
A workaround to this dilemma could also be to store links to cloud storage (eg dropbox) with the first file of each category (00) which could be a basic summary of that category with links to all content within that category.
This way, it also acts as an index and table contents for each category. In addition, it reinforces an organizing habit where as you update your knowledge base, you add a new piece of info to the summary page. And lastly, it can be helpful as a presentation tool if you want to send someone a one to three page document with links and summaries to all major work you’ve done in that category.
Yep, a good idea. The zeros can be used all the way down the tree like this.
I always define category 00 Index. And now you can store whatever in there. 00.00 JD index is always the master index for the whole system. And if I’m keeping that index elsewhere — say Airtable — I should link to that place from this file.
AC.00 can be a more specific index for any given category if required. Or A0.00 for the whole area.
I don’t understand the logic there. Does the AC.ID-name system function as an index? If that system is well designed for your use case, you can find the files (.docx, .xlsx, .eml, .png, etc.) by just following the right path along the numbers.
And if you cannot find a file (assuming it exists in the system), then either the file is miscategorized or the system needs fine-tuning.
But what if you’re tracking a thing in your system that isn’t a file at all? What if it’s an email, for example? Or a physical thing?
The ‘your file system is your index’ thing only works if every thing that you track has a file in your file system. (Which could be the case! Or perhaps you could create an empty folder to track stuff recorded elsewhere, but you have to remember to do that.)
Or – more relevant at work – I often have systems where I’m keeping files in separate locations. Depending on what the file is. That’s a pain, but it happens. Then you need an index.
OK, clear. I have been on a somewhat different wavelength in that I only think in terms of having everything electronically, having gone paperless some 6 years ago.
So, I file important emails as .eml files, I don’t buy physical books anymore, only electronic ones, etc. I do still have physical books but have to bothered to categorize them as I don’t feel the need for it.
Bottom line: I did not miss anything with the index principle, it is dependent on what system one uses.
@johnnydecimal subsequent to my previous comment I discovered the amazing Drag-n-drop J.D Index Generator, which gives an overview of all your AC.ID’s without the files in them. So, the name is a bit misleading in that it is not a full index, but what is shows me is the organizational tree, and the consistency, or in some cases lack of, my naming and numbering.
The only thing that I find disappointing is that when the browser cache is cleared all the data one put in is gone. I googled to see if there are ways to save that particular part of the cache but was unsuccessful. The owner, @ekafyi, seems to have forgotten about this or abandoned it.
Do you know of a way to save input data such that it can be re-used after cache clearance?
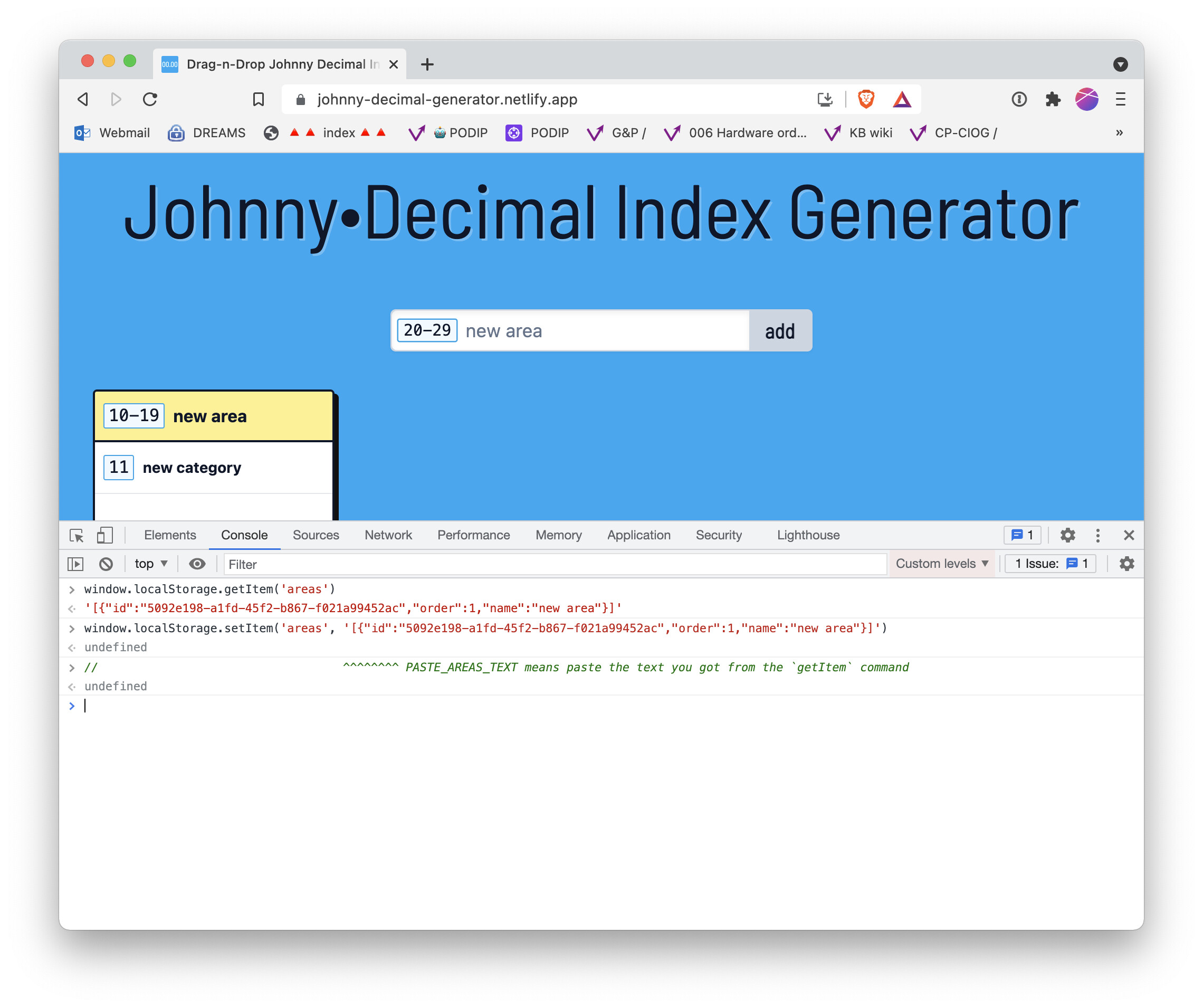
Yes, you can do it by using the browser console and grabbing the items from localStorage. It’s a bit clunky but it works.
I’m working and on a screenshare just now, I’ll knock up a quick video later.
Actually I’ll just try as text and you can let me know if you need a video (which I’m happy to do). I’ll assume basic knowledge of the browser console.
Create some sample data that you don’t mind losing (we’ll delete your cache as a test). Use a different browser if you don’t want to affect your actual system.
Open your browser’s console.
Run these two commands and save the output to a text file:
window.localStorage.getItem('areas')
window.localStorage.getItem('groupedCategories')
They will give you a bunch of text that looks like this:
@johnnydecimal thank you for that, I am relieved. I am using Brave browser (= Chrome fork), and to get to local storage`, you do
Cmd/Ctrl+I (= open dev tools) > Application
then in the left column click on Local Storage to expand.
The question then are:
how do you “grab” a copy? right-click does not offer that option;
when you have a copy of the local storage (in the case of @ekafyi’s netlify app there are 3 files), how do you re-use them after clearing the cache and the originals are gone?
Ah sorry, you’re doing this in your browser’s console. Cmd-Opt-I should bring that up for you, and then you want the Console tab. Here’s how it looks in Brave.
The PASTE... text is the text that you got from the previous getItem commands. So you get the text for those two items, save it, and if you need to restore it, you paste it in to the second two commands.
@johnnydecimal : bingo, the penny dropped with this slow dope. I got the 2 sets of data copied to a .txt file.
In the Console there is also groupedThings: is that of no importance? I ran a command window.localStorage.getItem('groupedThings') but it is a lot more data than the other 2 so I did not bother to copy it since you have not mentioned to do so. I just want to be sure I am not leaving important data unexported.
@johnnydecimal the groupedThings definitely needs to be copied and pasted back in too because that is where the IDs like 11.01 are saved.
In any case, your method works, which I am grateful for and want to thank you for.
The only thing is that one has to remember to make those copies before and/or after making changes. And, when one has to remember to do something, there is always a risk, not a small one, that one forgets. And changes cannot be undone, AFAIK. This is not a criticism, just a caveat for those using @ekafyi’s app.
Yeah this is definitely why @ekafyi calls this an ‘alpha’ version app. Use at your own risk! One day it might just disappear entirely and then even those exported files aren’t going to be much use. (Although you could reconstruct your system from them, the data is all there.)
It looks massively cool though. Love the aesthetic.