Hey everyone,
I’m still getting used to the Johnny.Decimal system and liking it so far, but I’ve hit a bit of a snag. What do you do when a project could realistically belong in two different categories? For example, a client job that also involves internal training material.
Do you just pick one and stick with it, or is there a clean way to cross-reference?
I try to stick with one place but are not hesitant to copy results and artefacts that might be useful elsewhere to another matching place. However I only do this if it is clear that these won’t change further because keeping things in sync is a pain.
If the client project contains some other stuff from your system – the internal training material – you have a few options.
If the training material is static, it’s okay just to copy it inside the project. And I suppose even if the training material then gets updated, the version delivered to the client probably doesn’t, so now you have two diverging sets of data but that reflects the actual state of the world.
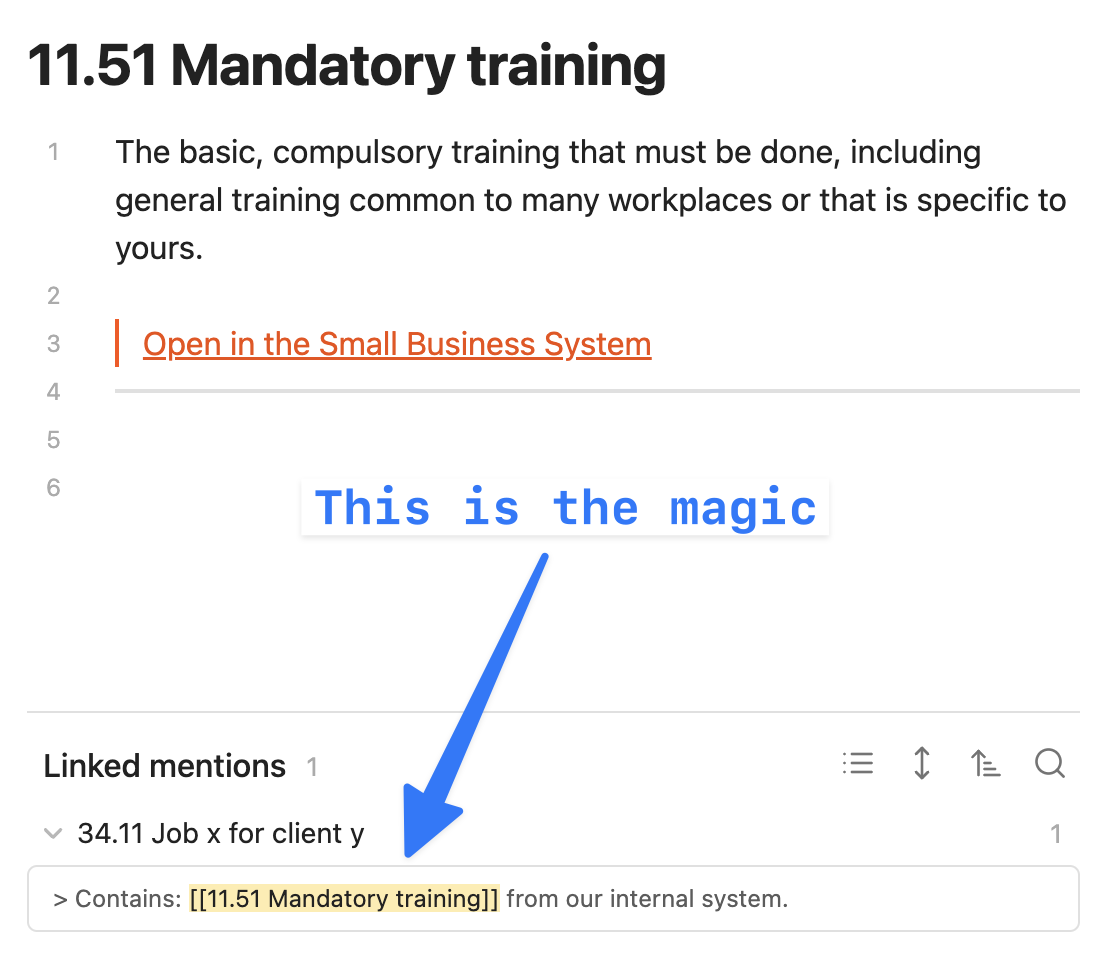
If you don’t want to do this, this is what your JDex is for. In the client job note, you can just reference across to the training material. This is why I recommend apps like Obsidian or Bear: they’ll automatically show ‘backlinks’ between documents.
The real trick here is remembering that these links exist. Backlinks are super powerful when you look at them!
Create them liberally and use them often.
Which way to link?
I have a blog post in draft for this, but the heuristic is to link ‘up’ from the thing that might get duplicated, to the thing that’s more static.
You’re way more likely to create another job than you are to create another ID for internal training material. So link that way. Because it can be convenient to duplicate note in your software when you create that new job, and then your links come along for the ride.
Some time ago I started using DEVONthink Pro (DTP) for everything related to file management. In DEVONthink I have a database relating to each role that I defined after I worked through David Spark’s Productivity Field Guide such as 20–29 Researcher or 30-39 Photographer. Each Database is usually self-contained. One of DTP’s strengths is the ability to replicate files and groups (folders) to other places in the database, comparable to aliases. It’s a representation of the same file (not duplicate/clone). If a file is relevant to another number/project for reference I simply replicate it to the other group.
Additionally to that I also use a tagging system (tp-TYPE such as tp-information or tp-note; s-STATUS such as s-active, s-draft or s-waiting; p-PROJECT; inst-INSTITUTION) and DTP has a neat way to quickly filter by tags (shortcut CTRL+T). The tagging seems to be a duplicate layer of file retrieval/management but it is quite handy to quickly find things and quickly filter relevant files. For example, I indexed my Bookends library under 20.08 Literature and tagged the relevant PDFs for p-Dissertation and tp-article, tp-book, s-reading_list or anything else that fits. I can then set up local Smart Groups according to tags and topics in 21.08 Literature in my 21 Dissertation group and/or replicate the relevant documents according to the categories I need.