I was going to type this as a reply to this post from @ontologist but that thread is about extend-the-end, and this question is about something entirely different. Here’s the key bit, from the end:
On to the question.
This is a problem I have – unresolved – with use of the headers that we introduced with Life Admin.
I have no problem with them in that context. That is an essentially fixed system. It is designed to be static. We left 2 IDs free under each header just in case, but the intent is, you use it like it came. Similarly, area 10-19 Business administration in the Small Business System.
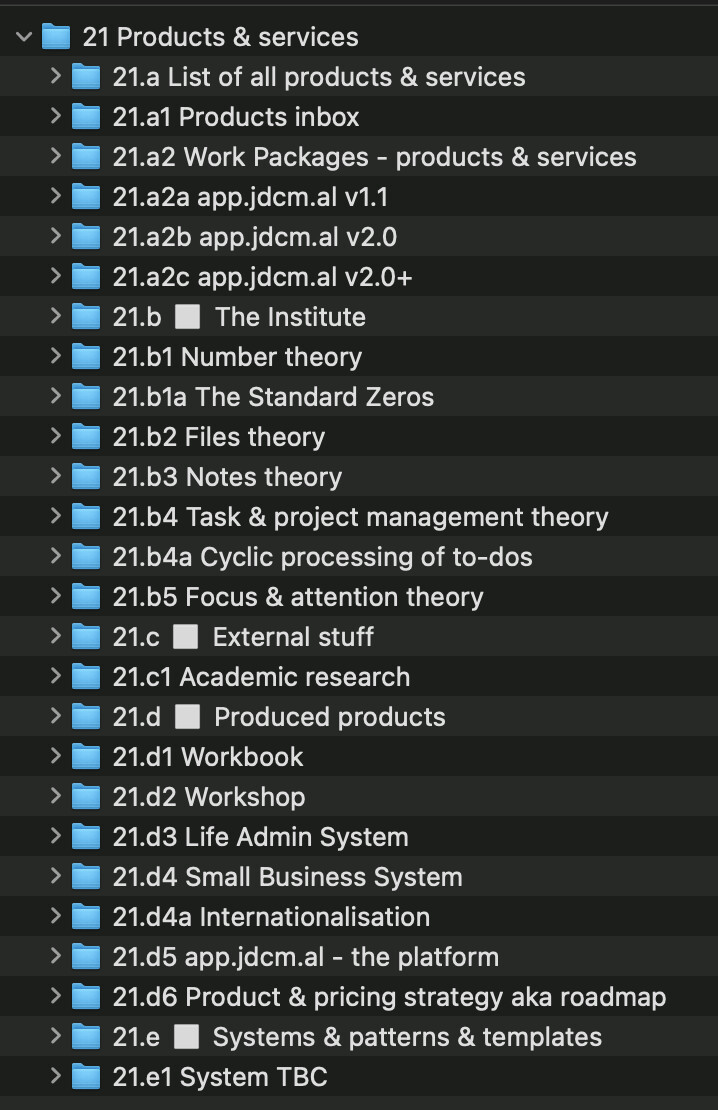
But then we have SBS category 21 Products & services 💈, which comes empty. Because I can’t define your products & services.
So I’m currently in the process of defining my own structure there. And when I use headers, which feels nice because I’m encoding a further level of semantics, I start to feel a little nervous. Because this isn’t a static system. I’m adding new IDs every day.
Here’s what I’ve got so far.

The problem
Of course is one of unpredictability. Here I sit, days in to this new structure, and how can I know what’ll be busy and what won’t?
Explaining this to others
As per the other thread, this feels like I’m straying in to unexplainable territory. Which is a red-flag. What rules, heuristics, guidance would I give you, other than to just spend a day trying to plan it before you start?
And would that be okay? Especially in this context where you’ve got SBS for free (mentally, not monetarily lol ![]() ) and so the only thinking you need to do is in this category context?
) and so the only thinking you need to do is in this category context?
So…
I think I’ve answered my own question. I think I’m going to roll back and abandon headers in this category. So IDs will follow the ‘old-school’ JD way: they’ll appear in the order that they were created, and will be all over the place. Number theory might follow Small Business System might follow Academic research. Whatever. Get over it.
Perhaps, then, I should at least put all of my old stuff at the top. The workbook, workshop, life admin, and small business systems, in that order, which is the order they were created. Then all the other stuff I just need to free-form, creating IDs as I go.
Agh. No. I don’t know. I read this over and over and my mind changes each time. Headers are so neat…
So I won’t change anything yet. I’ll post this and wait. The discussion in the other thread was tremendously useful.